基于Region Proposal的深度学习目标检测算法RCNN系列
RCNN (CVPR2014, TPAMI2015) -> SPP-NET (ECCV2014, TPAMI2015) -> Fast R-CNN(ICCV2015) -> Faster R-CNN(NIPS2015)
文章中的缩写: RP -> region proposal (候选区域) GT -> ground-truth (真实标签) IoU -> 目标检测指标 (两个框面积交集/两个框面积并集)
RCNN
RCNN 是RCNN网络的第一篇。是结合了CNN作为特征提取的物体检测,比传统的 HOG-based DPM等方法表现更突出,mAP(mean average precision)达到53.3%, 前者只有30%左右。
模型概括
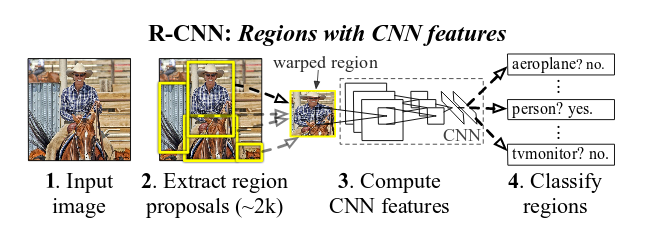
- 输入任意图片
- 在图像中确定约2000个RP (使用selective search算法选取)
- 每个RP内图像块缩放至相同大小,并输入到CNN内提取特征,将fc7层的输出作为特征
- 对RP中提取出的特征,使用分类器判别是否属于一个特定类,每一个框针对每一个种类都有一个分数(non-maximum suppression 算法选出合适的框)
- 对于属于某一特征的RP,用Bounding-box regression进一步调整其位置
训练过程
finetune
Alex Net:

借鉴在 ImageNet数据集上训练好的模型,finetune 成N+1种类的分类器(N个种类+1个背景),得到一个向量矩阵,文中使用的是AlexNet, 提取的是fc7后得到的4096维的向量。
- ILSVRC2013 detection dataset train (395,918), val (20,121), and test (40,152)
- 数据 与GT有大于0.5重合(>=0.5 IoU)的为正样本,其余的为负样本(数量多效果好)];
- 学习率 0.001
- batch-size 32正样本+96负样本,模拟真实情况中负样本会比正样本多得多
训练SVM
每一类训练一个SVM分类器
- 数据 只有GT为正样本,与GT有<0.3IoU的RP为该类别的负样本,落入中间部分的RP将被忽略
Bounding-box regression
得到SVM分数后,在feature map 上预测一个新的 bounding box。
因为选择出来的RP是很粗略的,与标注的GT存在一定的偏差,所以需要对RP进行微调,得到更加精确的框bounding box。
 方法是在已有的预测框P基础上,学习一个从P到GT的映射,得到更加准确的框,映射得到的结果设为\( \widehat{G} \)(图中的G)
方法是在已有的预测框P基础上,学习一个从P到GT的映射,得到更加准确的框,映射得到的结果设为\( \widehat{G} \)(图中的G)
设定映射中有四个参数\( d_x(P),d_y(P),d_w(P),d_h(P) \),可以理解为预测与映射的偏移量,我们可以通过平移和缩放得到映射!\( \widehat{G} \):
 预测框P在pool5得到的特征向量为\( \o_5(P) \)。
预测框P在pool5得到的特征向量为\( \o_5(P) \)。
\( d_x(P),d_y(P),d_w(P),d_h(P) \)是\( \o_5(P) \)的线性方程。\( w_\ast \)通过下面学习得到:
\[ w_\ast=\underset{w}{argmin}\sum_{i}^{N}(t^i_\ast-\widehat{w}^T_\ast\o_5(P^i))^2+\lambda\left|\widehat{w}_\ast\right|^2 \]
其中:
- \( t_\ast \)为预测P与GT的偏差,由下面公式计算得到:

- 给予val数据集选择 \( \lambda=1000 \)
- 只对与GT有大于0.6覆盖度的预测P进行bounding-box regression, 如果P与GT距离很远, 很难学习到一个线性映射对P进行调整
测试过程
- 与训练过程一致,得到有SVM分数的RP
- 每一个类别,采取non-maximum suppression的方法,选择最终的bounding box作为返回结果。
Non-maximum suppression
这里的non-maximum suppression方法是找出score比较高的RP,其中需要考虑不同RP的重叠问题。 假设有N个种类,提取2000个RP,通过CNN后得到2000 * 4096 的特征矩阵,然后通过N个SVM来判断每一个RP属于各个类的scores。其中,SVM的权重矩阵大小为4096 * N,最后得到2000 * N的一个分数矩阵。根据分数矩阵和RP的坐标信息,找到置信度比较高的bounding box。
- 对于每一个种类,计算出每一个bounding box的面积,根据分数排序,取出分数最高的bounding box。
- 计算其余bounding box与当前最大分数与box的IoU,去除IoU大于阈值的bounding box。同时删除分数较低的。剩下的为最终结果
- 有N个分类则计算N遍。
代码实现:(来自Ross Girshick大神的fast rcnn)
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep
Reference
- Rich feature hierarchies for accurate object detection and semantic segmentation Tech report
- blog.csdn.net/danieljianfeng/article/details/43084875