基于Region Proposal的深度学习目标检测算法
RCNN (CVPR2014, TPAMI2015) -> SPP-NET (ECCV2014, TPAMI2015) -> Fast R-CNN(ICCV2015) -> Faster R-CNN(NIPS2015)
文中缩写 spp: spatial pyramid pooling
SPP-Net
解决问题:
- 在此之前用CNN提取特征需要输入规定大小的图片(如:224 * 224),保证后面的模型设置(全连接层)一致,所以一般会对图片进行截取或者缩放,这样的操作会导致最后的图像识别准确率下降。
- 基于CNN的物体检测模型RCNN是在截取图片不同区域后缩放至一样大小后各自进行特征提取,重复提取特征用时较长。

解决效果:
- 允许输入任意大小的图片,每张图片仅经过一个CNN提取特征,在特征上选取不同大小的区域,生成长度一致的representation。
- 速度上比RCNN快24-102倍,可以做到0.5s处理一张图片,同时保留了图片大小差异带来的更多信息,在Pascal VOC 2007预测准确率更高。
模型概括

- 模型设计:将最后一层卷积层后的pooling层(文中为conv5后的pooling)改成spatial pyramid pooling layer,输出长度一致向量输入全链接层进行分类
- 固定前面的卷积层,finetune后面的全链接层。
- 图像识别:使用的训练数据可以使缩放不同大小的图片, 例如缩放至{224, 256, 300, 360, 448, 560},然后每种大小的图片截取224*224大小的区域训练
- 目标检测:没有data augmentation,但在SVM训练中加入L2正则
spatial pyramid pooling layer
全连接层或在SVM/softmax这一类的分类器需要输入规定长度的向量,可以用 Bag-of-Words (BoW),或者改进的 Spatial pyramid pooling,后者可以保留特征的位置信息。
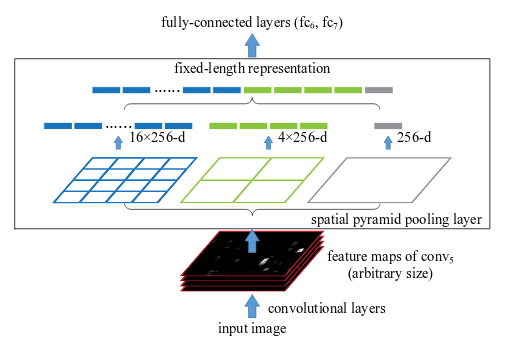 图中选择的是Alex-Net,conv5得到的feature map大小是w * h * 256, 所以是256维向量
图中选择的是Alex-Net,conv5得到的feature map大小是w * h * 256, 所以是256维向量
pooling使用max pooling,具体操作如下:
- 假设conv5输出feature map大小为 a * a,pyramid level层数为P,每一层大小为 n * n 个bin (每一层不同)
- max pooling滑窗大小为\( win = a / n \) (向上取整), \( stride = a / n \) (向下取整)
- 得到P层pyramid level池化后结果叠加起来成为一个\( \sum_i^P bin_k * 256\)矩阵,作为fc6的输入 例如:
| a*a | P | P个n*n | P个win | stride | fc6输入 |
|---|---|---|---|---|---|
| 13*13 | 4 | {6*6, 3*3, 2*2, 1*1},一共50个bin | {3, 5, 7, 13} | {2, 4, 6, 13} | 50*256 |
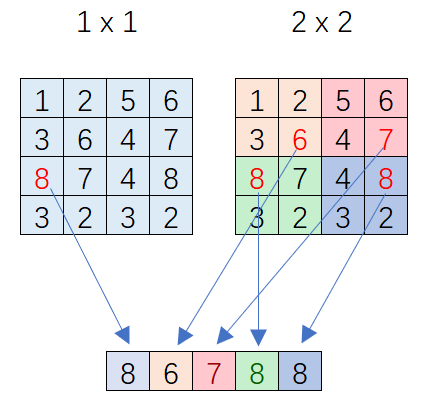
画了一个feature map 为4*4的例子,P=2,n*n = {1*1, 2*2}:
代码实现:
import tensorflow as tf
import math
def Spp_layer(feature_map, bins):
'''
sppnet for object detection, output: pooling feature map
- input_feature_map: feature map of the last conv layer
- bins: list of n for each pyramid level
eg: [3, 2, 1] denote 3*3, 2*2, 1*1 bins
'''
# get feature map shape
batch_size, a, _, _ = feature_map.get_shape().as_list()
pooling_out_all = []
for layer in range(len(bins)):
# calculate each pooling layer
k_size = math.ceil(a / bins[layer])
stride = math.floor(a / bins[layer])
pooling_out = tf.nn.max_pool(feature_map,
ksize=[1, k_size, k_size, 1],
strides=[1, stride, stride, 1],
padding='VALID')
pooling_out_resized = tf.reshape(pooling_out, [batch_size, -1])
pooling_out_all[layer] = pooling_out_resized
feature_map_out = tf.concat(axis=1, values=pooling_out_all)
return feature_map_out
Reference
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition