gpu,cpu差别
在优化线上模型部署的时候遇到了cpu,gpu并发跟不上的问题,所以特意研究了一下gpu,cpu差别。把整合的内容记录下来,分别有硬件,软件角度分析。
硬件
GPU为什么设计的
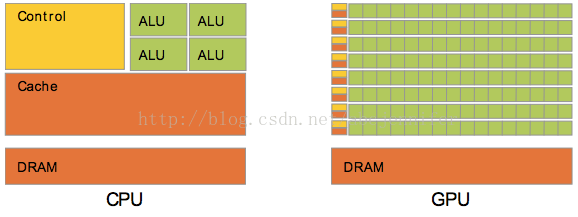
GPU的设计主要针对解决那些可以分解成成千上万个小块并且可以独立运行的问题,适用于计算量大,简单,多并行的计算。所以设计了很多小的数据单元执行同样的任务。
GPU由多个流处理器簇(SM)排列组成,而每个流处理簇又由多个流处理器(SP)组成。SM可以看成是一个CPU的核,如果持续增加SM的数量,GPU性能会持续提高。
而CPU的设计主要是用来运行少量比较复杂的任务。设计上是典型双核或者四核设备,有数据Cache和流程控制器。能够处理多任务串行的问题。
线程上设计
CPU,GPU支持线程的方式不同,CPU每个核只有少量寄存器,在执行多任务的时候, 上下文比较昂贵,因为需要将寄存器里的数据保存到RAM,重新执行任务时,需要从RAM中恢复。 而GPU上下文切换只需要设计一个寄存器组调度着,用于将当前寄存器里的内容换进换出, 速度比保存到RAM快好几个数量级。
CPU在线程数增加的时候,上下文切换时间会很多,通常这个时候在进行I/O操作或者内存获取, 这个时候CPU会被闲置。而GPU采用的是数据并行模式,他需要成千上万的线程操作。利用有效 的工作池保证GPU不会被闲置。GPU默认是并行模式,SM每次可以计算32个数,而CPU只计算1个。 GPU的每个SM都有一个内部访问的共享内存和寄存器,SP与寄存器交流速度很快,几乎不用等。 处理的数据可以在放在共享内存,不用担心上下文切换需要转移。
如果选择gpu (2018-08-25更新)
这是Tim Dettmers的一篇博客的记录里面提到的怎么选择不同的gpu, 详细内容可以参见blog, 这里想记录一些重要信息,和一些概念的东西.
concepts
TFLOP
TFLOP是“teraflop”的缩写, teraflop是指处理器每秒进行一万亿次浮点运算的能力, 例如, “6 TFLOPS” 指这个处理器一秒能进行6万亿次浮点运算.
FLOPS
FLOPS表示处理器一秒内能处理多少浮点运算.
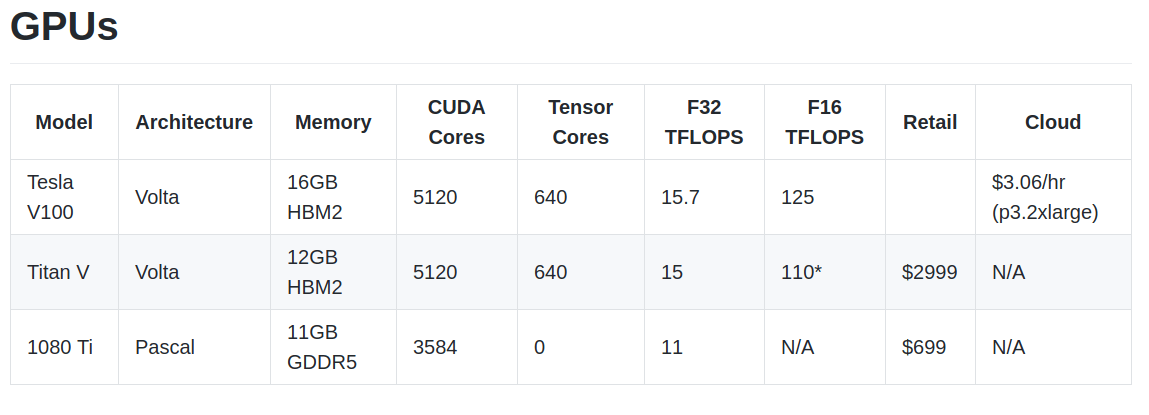
市面上三款GPU的参数比较
takeaways
- 多d个GPU使用时如果没有加入并发算法的话速度不会得到提升, 比较好的做法是, 每个gpu执行不同的算法或者参数, 等你选择好了, 再设计并发算法在多个GPU上训练最后的模型.
- 通过带宽(bandwidth), FLOPS, and 张量计算核心(Tensor Cores) 可以评价一个 GPU的性能.
- GPU可以加速矩阵和卷积计算, 其中矩阵运算受限于带宽. 如果你要执行LSTM或者其他RNN等涉及很多矩阵运算的网络, 那么带宽很容易成为瓶颈. 而ResNets和其他的卷积结构的话, TFLOPs会成为瓶颈.
- Tensor Cores会加速运算, Tensor Cores的设计是用来加速计算, 但是跟带宽没有关系. 卷积可以加速 30-100%. 而且Tensor Cores可以使用16-bit进行计算, 相对与32-bit而言, 同样的宽带可以执行两倍的计算, 所以LSTM等的计算可以提速20-60%左右.
- 总的来说RNN看带宽, CNN看FLOPS, Tensor Cores可以加速运算, 但是没有条件可以忽略, 非需要不买Tesla.
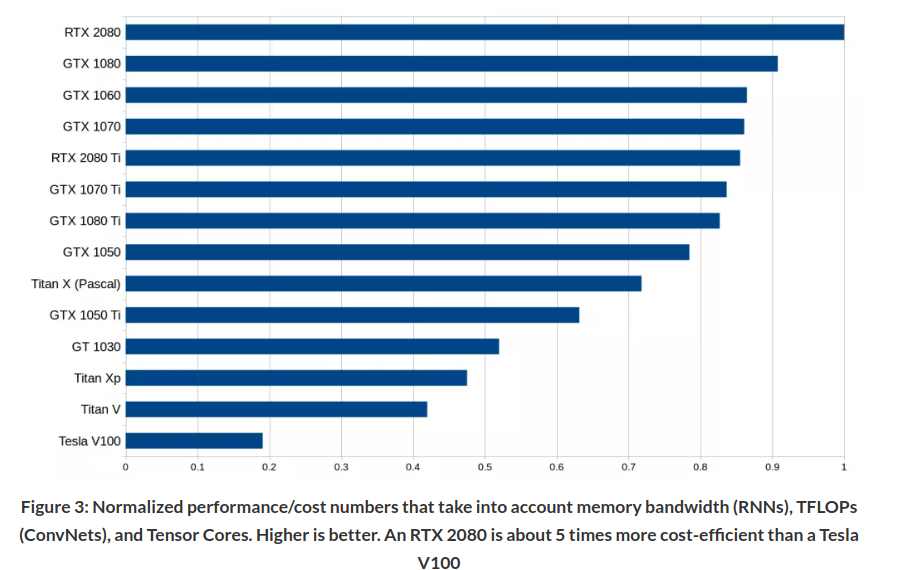
gpu建议

Reference
- https://blog.csdn.net/abcjennifer/article/details/42436727
- http://timdettmers.com/2018/08/21/which-gpu-for-deep-learning/
- https://www.digitaltrends.com/computing/what-is-a-teraflop/