最近做了一些情绪识别的调研工作, 最主要是做人脸2D图像的情绪识别, 不包括视频,3D,脑电图等的研究, 当然, 时效性什么的我们就不考虑了哈~~
一些有用的网站
研究文献
DAGER: Deep Age, Gender and Emotion Recognition Using Convolutional Neural Networks (2017) (不推荐)
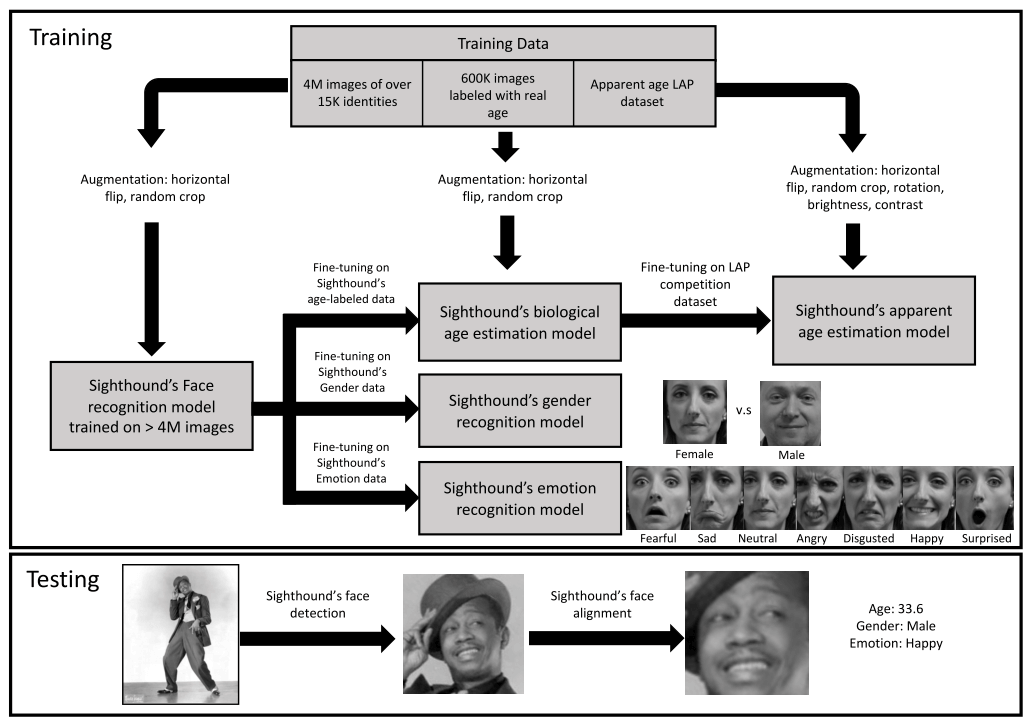
作者提供了一个pipeline识别图片中人物年龄,性别和情绪. 使用了40,000个人的4,000,000张图片进行训练.
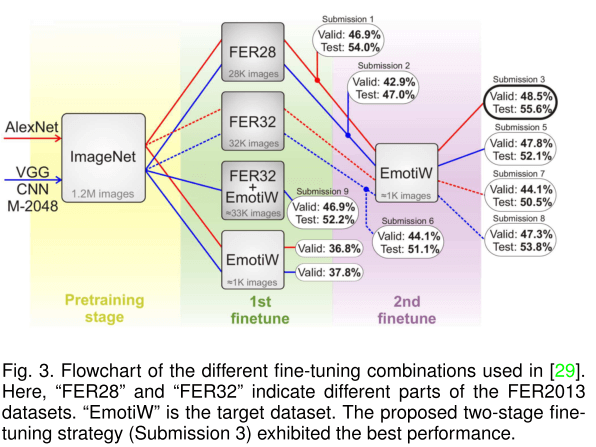
全问文有点价值的可能是下面这张流程图…其他都在吹捧自家API(喷…)
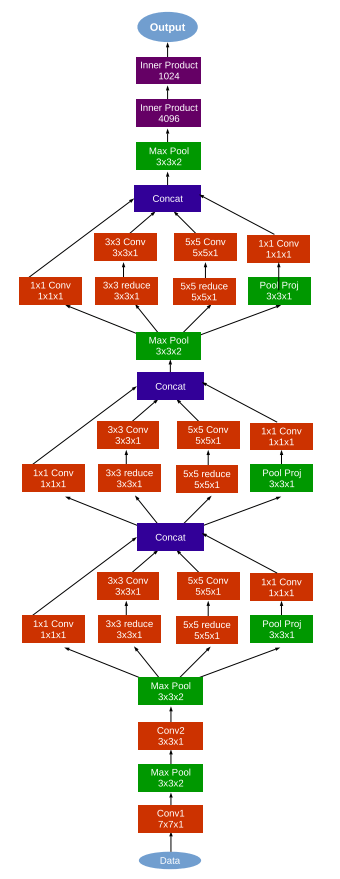
Going Deeper in Facial Expression Recognition using Deep Neural Networks (2015)
模型
与inception类似的CNN网络
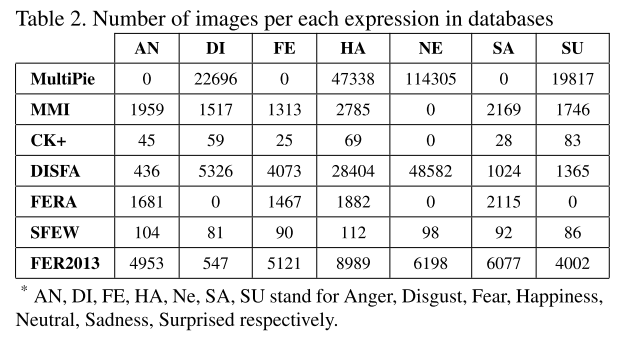
数据集
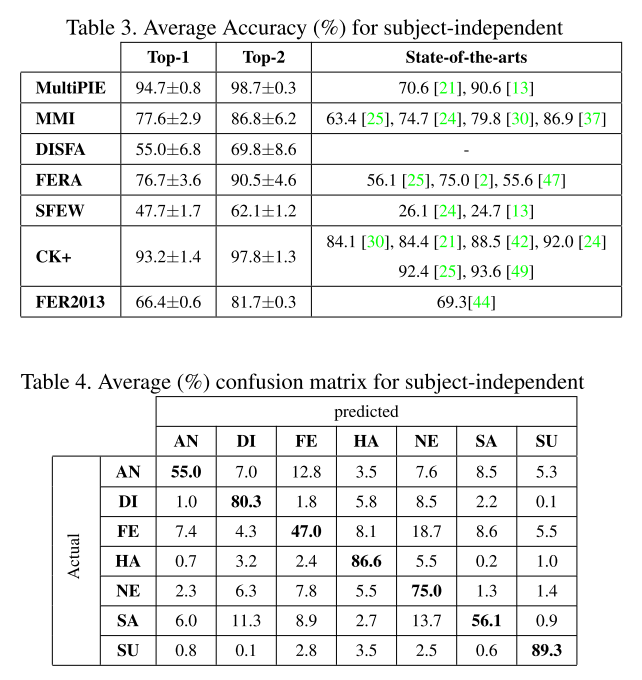
实验流程
- bidirectional warping facial landmarks Active Appearance Models (AAM) 得到人脸局部体验 , 之后可以使用IntraFace(SIFT)
- 图片裁剪后缩放至48 x 48后进行图片增强: 四个边角及中间裁剪出40x40大小的图片并进行左右翻转
- 模型训练
结果
Spatio-Temporal Facial Expression Recognition Using Convolutional Neural Networks and Conditional Random Fields (2017)
这篇论文与上面是同一个作者.
模型
Residual connections 残差网络 + linear chain Conditional Random Fields (CRFs) (条件随机场)
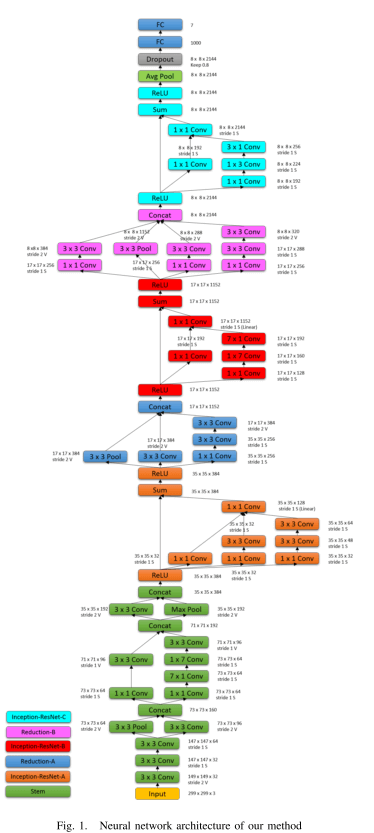 CRF连接在最后一个fc后面
CRF连接在最后一个fc后面
数据集
MMI, extended CK+, GEMEP-FERA
流程
- bidirectional warping facial landmarks Active Appearance Models (AAM) 得到人脸局部体验
- 裁剪图片至 299x299, 更小的图片效果反而不好
- 模型训练
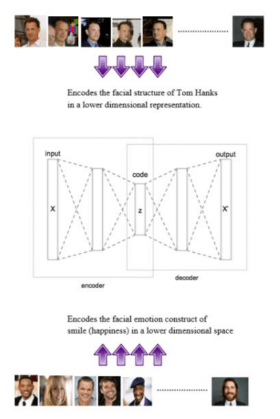
Facial Emotion Detection Using Convolutional Neural Networks and Representational Autoencoder Units (2016)
本文比较了用AE(autoencoder, 自编码器)和CNN
模型
AE + cnn
数据集
JAFFE
流程
- 图片缩放至64 x 64, 每一类表情的所有图片进入AE后得到该表情的特征向量, 一共是七个
- 测试: 测试图片进入AE后得到特征向量, 与该七种向量计算余弦距离
- CNN部分: 主要提到做了数据增强, 把64 x 64的图片遍历成48 x 48的图片.
结果
CNN结果比AE结果好很多
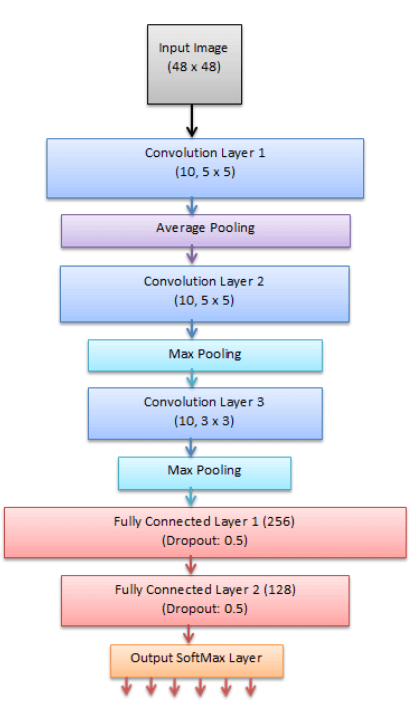
Facial Expression Recognition using Convolutional Neural Networks: State of the Art (2016)
这篇文章主要讲了解释了, 比较了6种用于FER的模型, 在FER2013数据集中得到了75.3%的结果
基本数据预处理差异
下面是预处理的主要流程, 有的会缺少部分环节, 且使用方法不用. 但是文中剔除, 有时候做人脸对齐会提升模型准确度.
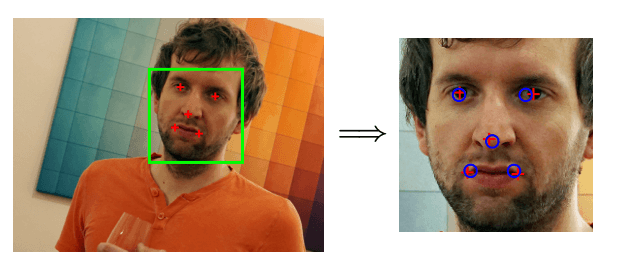 face detection (green square), facial landmark detection (red crosses), registration to reference landmarks (blue circles), and illumination correction.
performances, illumination correction
人脸检测 – 人脸特征点检测 – 人脸对齐 – 光线矫正?(最后一个不知道怎么翻译)
face detection (green square), facial landmark detection (red crosses), registration to reference landmarks (blue circles), and illumination correction.
performances, illumination correction
人脸检测 – 人脸特征点检测 – 人脸对齐 – 光线矫正?(最后一个不知道怎么翻译)
模型结构
所有网络的模型都比较浅, 在4-11层之间, 文中提到的是, 针对FER的训练, 网络不需要很深就能够提取高级特征. 其中结果比较好的模型具备: 网络层数不深(5,6层), 加入额外的数据, 使用人脸特征点对齐, 使用比较复杂的数据增强.
本论文的实验条件
- 在网络层中加入BN, 最后一层fc前加入dropout
- 数据处理: histogram equalization(增加对比度) + 归一化 , 注意这里没有加入特征点提取
- 数据增强:左右翻转, 随机裁剪48 x 48局部图片
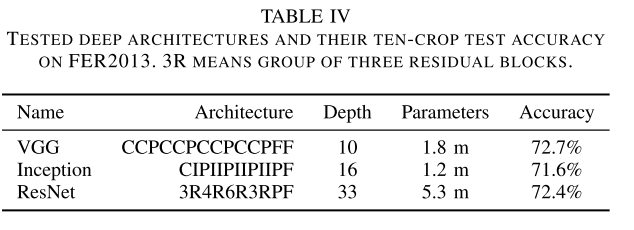
本文模型
最后文章觉得跟加深的模型应该效果更好, 实验了VGG, Inception, ResNet三个类似的网络, 效果都在71%以上. 融合后结果达到75%
Deep Facial Expression Recognition: A Survey (2018)
这是一篇18年的综述,涵盖了很多之前的论文进展,只有
预处理
- 人脸检测
- The Viola- Jones (V&J) face detector
- 人脸对齐
- IntraFace
- Zhu and Ramanan’s mixtures of trees (MoT) structured models
- discriminative response map fitting (DRMF)
- Dlib C++ library
- multitask cascaded convolutional networks (MTCNN)
- DenseReg
- Tiny Faces
- 数据增强
- rotation, translation, horizontal flips, scaling and sheer.
- noise such as salt&pepper and speckle
- brightness and saturation
- 2D Gaussian distribution
- 图片归一化
- Illumination normalization:
部分的文章使用了histogram equalization增强图片对比,对于前景和背景相似的图片来说,效果较好
- Pose normalization:
得到表情的正面的图
模型结构
- Pose normalization:
得到表情的正面的图
- CNN
- DBN (Deep belief network)
- DAE (Deep autoencoder)
- RNN
state-of-the-art
- pre-training and fine-tuning
 使用更多的数据与训练模型会有更好的效果
使用更多的数据与训练模型会有更好的效果 - 加入更多的特征信息 SIFT, LBP, AGE, HOG
- 网络结构
- 结构: CReLU, 残差, inception,
- 损失函数: island loss, locality-preserving loss, triplet loss
- 模型融合
- 多个模型的feature map 合并
- 投票, 概率取均值, 权重取均值
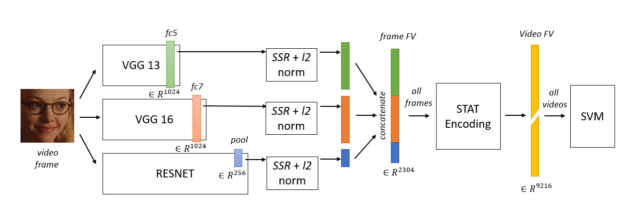
- 多任务模型
- 级联模型
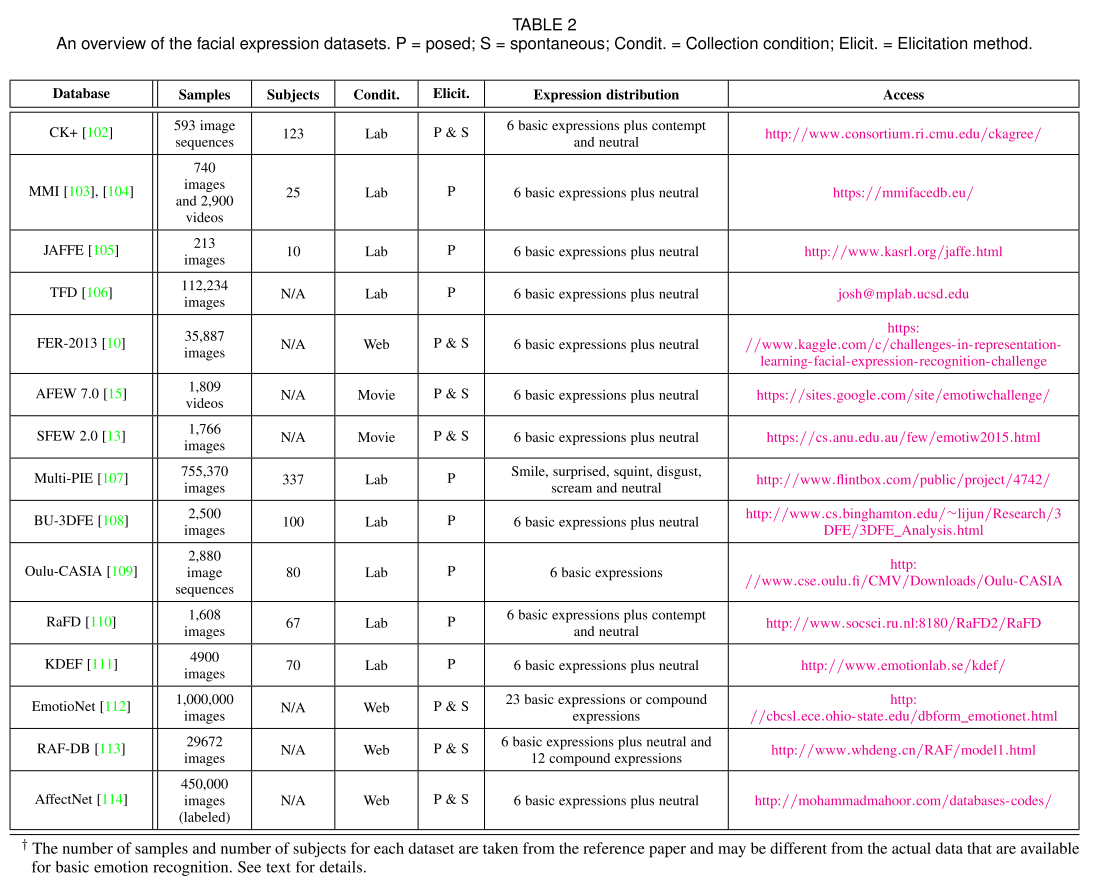
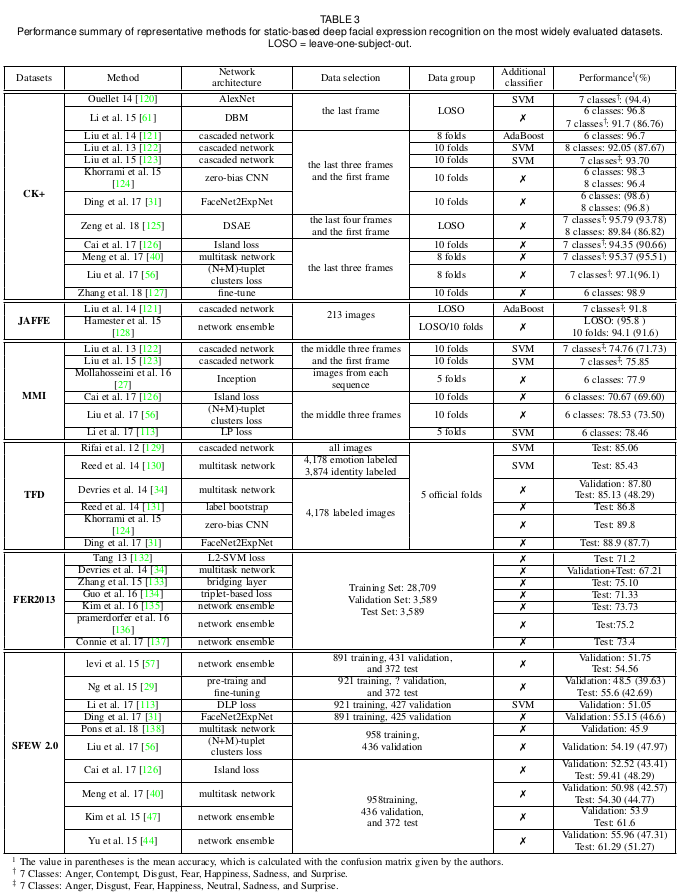
数据集
Reference
- https://blog.produvia.com/recognizing-emotions-using-artificial-intelligence-62b2ea7928a7
- https://docs.opencv.org/2.4/doc/tutorials/imgproc/histograms/histogram_equalization/histogram_equalization.html