Haar Classifier
这是基于Haar feature的cascade分类器, 出自Paul Viola和Michael Jones的论文, “Rapid Object Detection using a Boosted Cascade of Simple Features”. 有的资料也描述为Viola Jones face detection. 是一个基于机器学习的传统图像处理算法, 笔者在做情绪识别的时候需要用到人脸检测, 一开始用的就是这个模型, 速度十分快, 但是准确度上还有一点欠缺… 但还是觉得很有学习必要哒~~
Haar-like feature
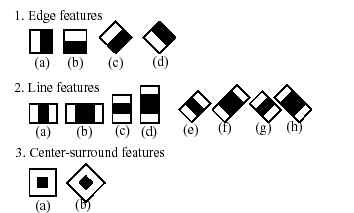 Haar-like feature和卷积核类似, 用于提取特征. 黑色表示-1, 白色表示1, 每个feature计算得到一个值.
Haar-like feature和卷积核类似, 用于提取特征. 黑色表示-1, 白色表示1, 每个feature计算得到一个值.
具体的做法是, 给定一个灰度图(0-255), 将feature作用于图片的每个区域, 效果就是计算了白色和黑色部分对应的像素和, 并且对比各个区域的差异(白的减去黑的). 直到Haar-like feature遍历完所有像素.
上图的特征在可以不断变化, 比如加多几个像素的白色, 或者黑色, 任意组合, 最后在一张24x24的图片上, 可以得到16000+的feature类型. 如下图:

下面图中显示了两个feature, 第一个feature选择眼睛的部分,因为眼睛的位置比较鼻子和脸颊更黑一点. 而第二个feature选择的是眼睛, 眼睛的地方比较黑, 而鼻梁位置比较白.
 更多例子:
更多例子:

integral image
因为每张图片每个区域都需要求和, 作者引入了integral image, 就是每个像素点的值, 是该像素点左上角所有像素点的和.
这样, 无论图片多大, 需要计算一个区域, 只要使用四个点的位置就可以了, 避免了很多重复的计算.
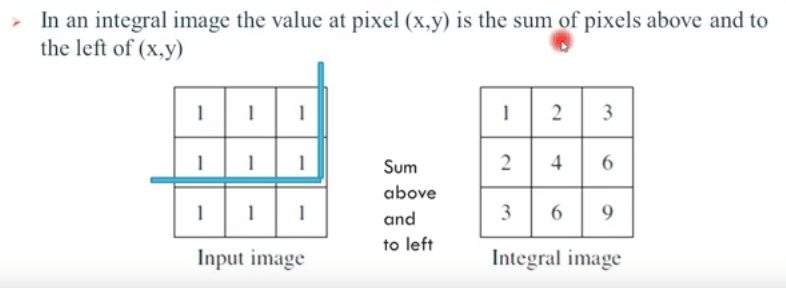 例如下图D面积对应的像素和, 只需要用4-2-3+1就能得到对应的求和. 方法十分巧妙!
例如下图D面积对应的像素和, 只需要用4-2-3+1就能得到对应的求和. 方法十分巧妙!

Adaboost
但是遍历完了所有像素, 会得到很多的特征, 如何去选择特征呢? 比如下图, 左边feature是相关的, 右边的相关性就很低.

因为上面结果会生成很多的feature, 需要加入Adaboost得到重要的特征.
我们可以将Haar feature看作是是一个个弱分类器, 通过给这些分类器不同的权重可以组合成一个强的分类器,
只要这个feature的加入让分类器表现比随机猜测结果要好就算是一个可以接受的feature.
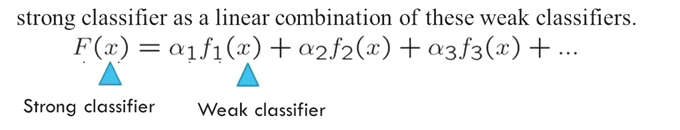
下面解释一下Adaboost:
首先, 模型一开始给每一个样本同样的权重
 使用一个弱分类器, 给样本做一次分类, 使带权重的损失最小
使用一个弱分类器, 给样本做一次分类, 使带权重的损失最小
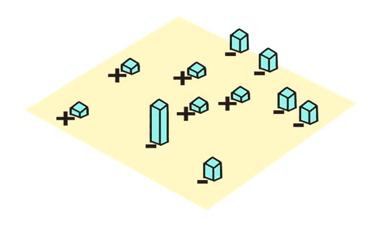
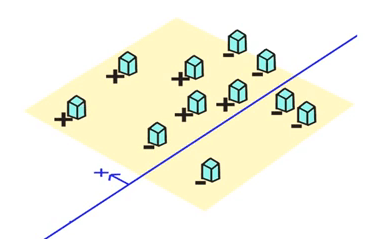 这一次分类中, 有三个被错误分类了
这一次分类中, 有三个被错误分类了
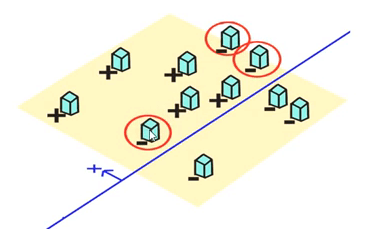 在执行下一次分类前, 增加这三个的样本
在执行下一次分类前, 增加这三个的样本
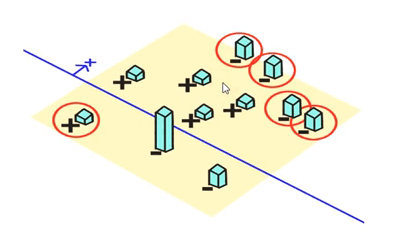
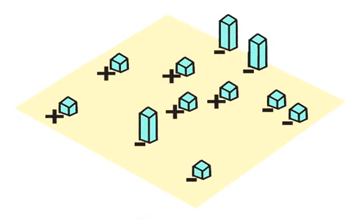 重复上面的过程, 第二次分类中有四个被错误分类了
重复上面的过程, 第二次分类中有四个被错误分类了
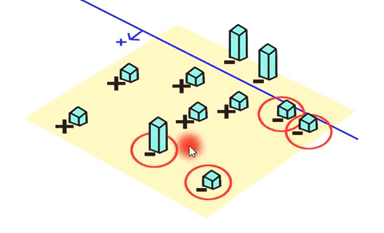 错误样本的权重再次调整
错误样本的权重再次调整
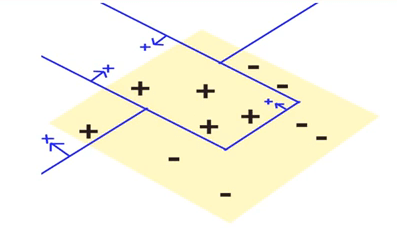
 再次分类
再次分类
 最后, 汇总多次分类结果:
最后, 汇总多次分类结果:
 最终得到的模型为所有弱分类器带权重的求和:
最终得到的模型为所有弱分类器带权重的求和:

Adaboost针对每一个feature, 训练出一个阈值, 用于判断是否人脸部分. 这个过程中会有很多误判的feature, 但只选择误差最小的feature.
这样可以将feature数目缩小到几百. 选出来的feature在进行线性组合得到最后的模型. 具体参考下面的伪代码:

Cascade
假设经过Adaboost筛选后, 从160000个feature缩减到6000个, 但是每24 x 24的窗口都要计算这6000个特征的话, 会非常低效的. 所以作者使用Cascade of Classifiers.
得到的6000个feature分成几个组, 把一张图片的检测分成几个stage, 每个阶段对应一组feature. 每一个stage会判断该窗口是不是人脸, 如果不是, 会尽快的排除掉, 节省时间.
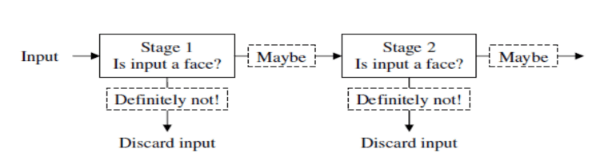 cascade 需要确定几个参数: stage个数, feature个数, 每个feature阈值
cascade 需要确定几个参数: stage个数, feature个数, 每个feature阈值
而最重要的是, 怎么判断哪些feature应该分到哪个stage, 一般来说, 先选强分类器放在前面的stage.

所以整个过程如下图:
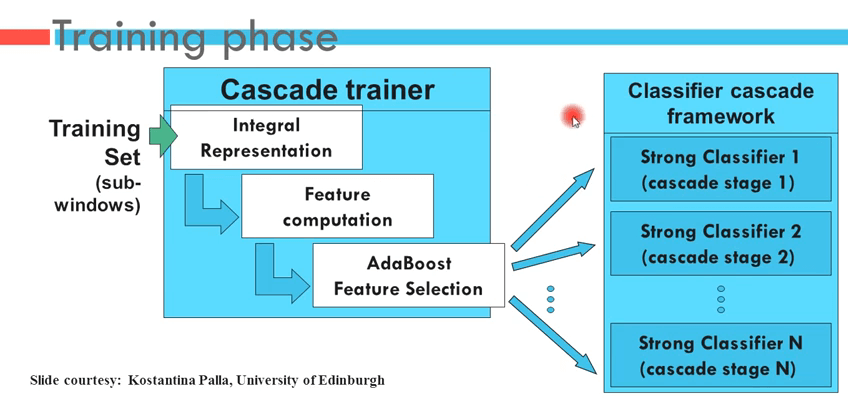
训练的时候需要加入尽可能多的(一般1000以上)正样本(背景, 没有人脸的图片)和负样本图片(有人脸的图片)(比例1:1). 正样本中记录人脸的位置.

opencv使用
具体参考opencv官网十分容易, opencv提供训练好的模型’haarcascade_frontalface_default.xml’, 只需要下载模型就可以直接用了, 如果需要自己训练也可以. https://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html
Reference
- https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
- https://www.superdatascience.com/opencv-face-detection/
- https://docs.opencv.org/2.4/modules/objdetect/doc/cascade_classification.html
- https://docs.opencv.org/trunk/d7/d8b/tutorial_py_face_detection.html
- https://www.youtube.com/watch?v=WfdYYNamHZ8 (截图大部分来自这个视频, 很推荐入门观看)