这次介绍Depthwise Separable Convolution, 这种卷积层的设计是为了减少参数和计算量, 同时提高准确度或者保持准确度. 其中有几个轻量级模型, 包括MobileNets(v1, v2), Xception, 他们的设计初衷都是为了能够简化模型, 提高模型速度和准确度. 这几个模型都使用到了depthwise separable Convolution.
Depthwise Separable Convolution
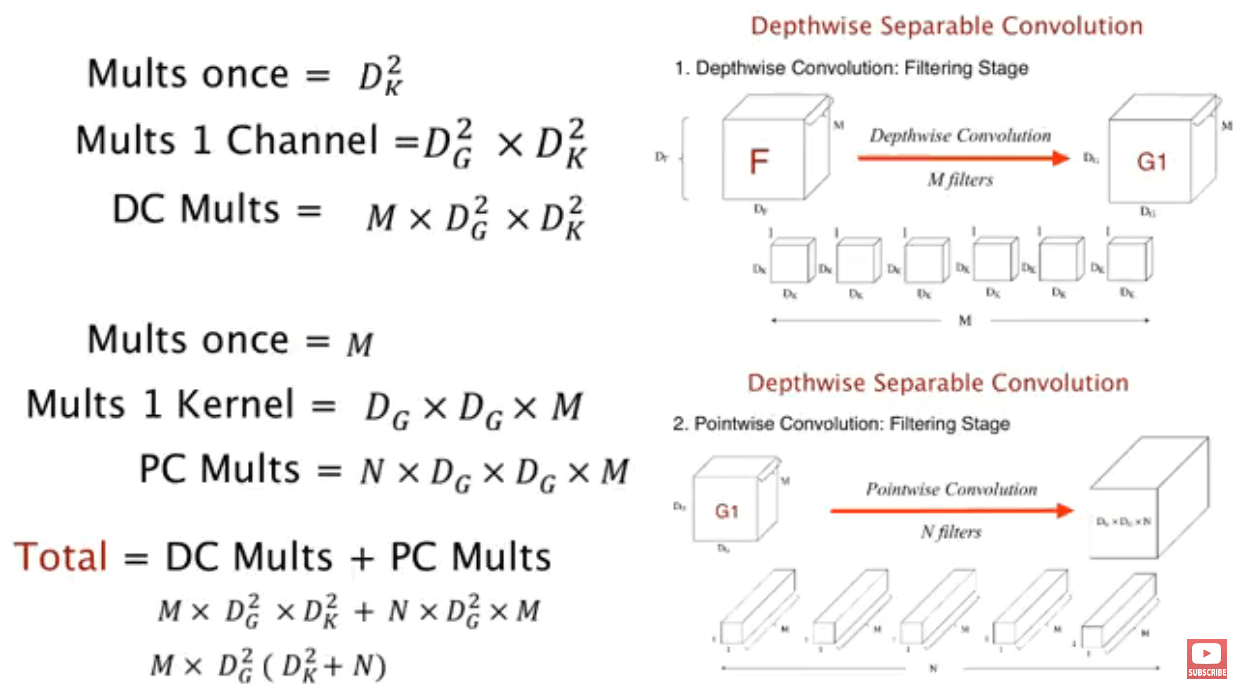
一个标准的卷积层是在给定 D_F × D_F × M 的feature map上用 N 个D_K × D_K × M的卷积核进行卷积得到一个 D_G × D_G × N 的feature map.
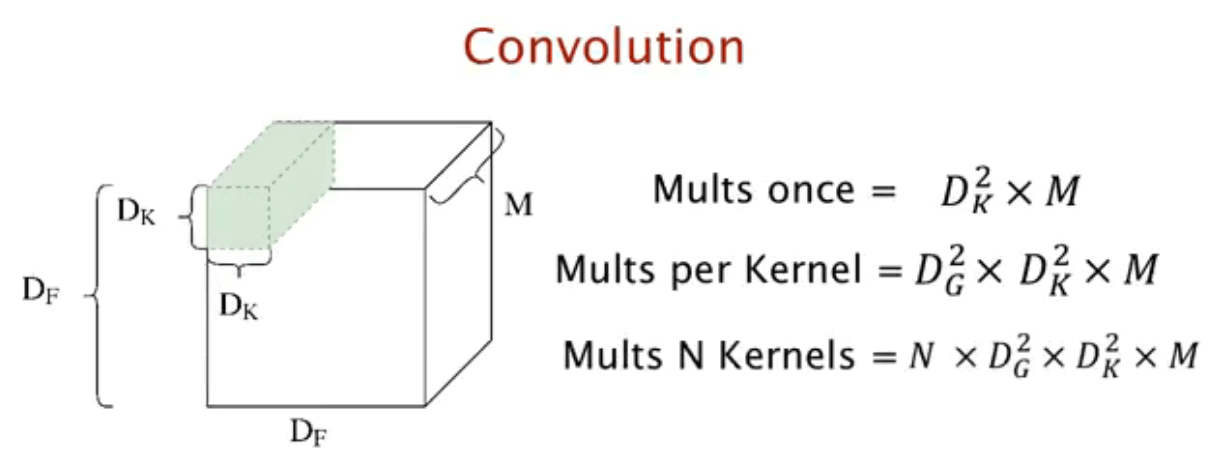
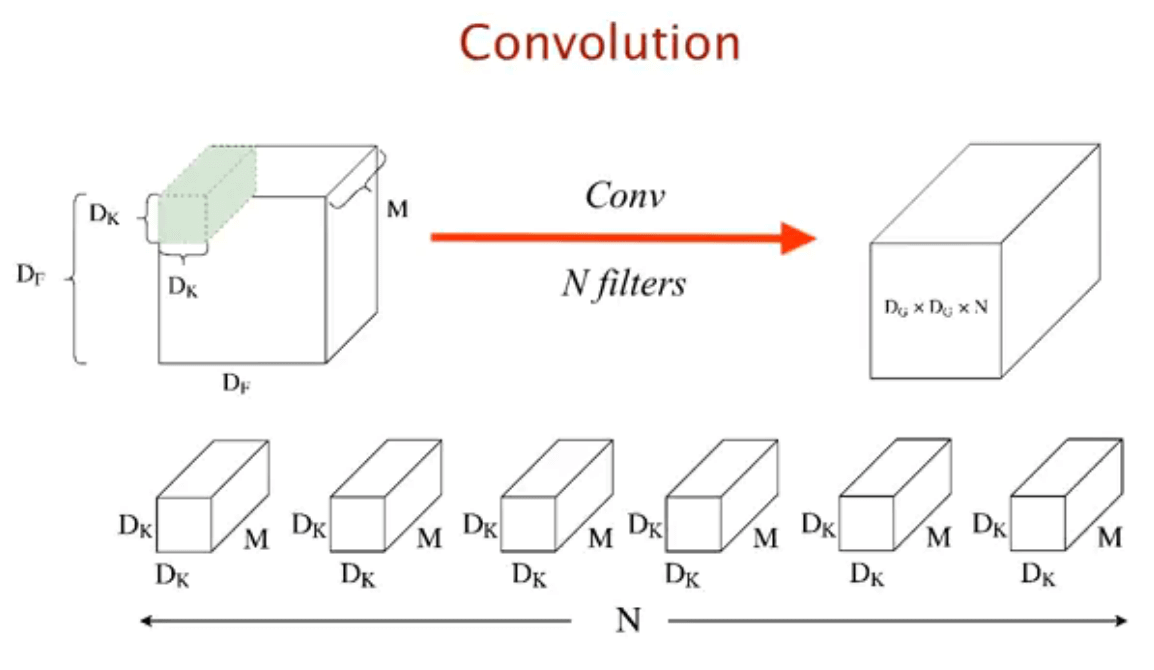 所以整个流程下来需要D_K ·D_K ·N ·D_F ·D_F ·M的计算量
所以整个流程下来需要D_K ·D_K ·N ·D_F ·D_F ·M的计算量
而Depthwise Separable Convolution把这个卷积步骤拆分成2部分, depthwise convolution 和 pointwise convolution(一个 1×1 convolution)
depthwise convolution
depthwise convolution 是使用 D_K × D_K 的卷积核对feature map 的每一层卷积, 每一个卷积核对应一层, 所以有M个. 结果得到一个D_G × D_G × M的feature map.
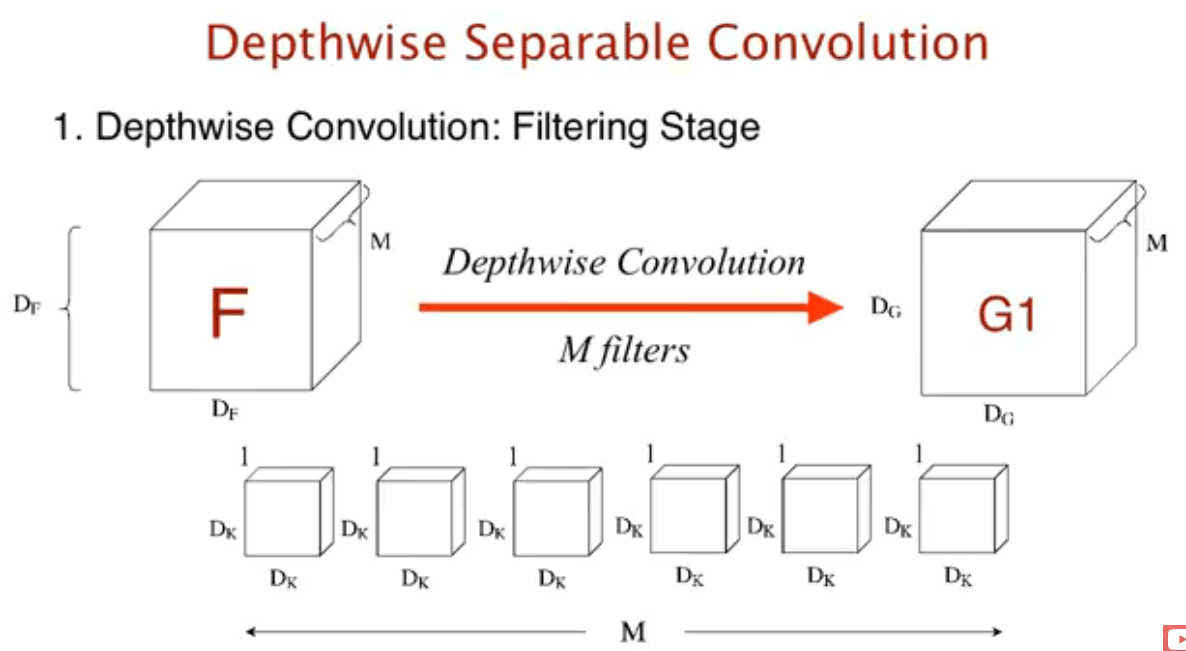 这一部分的计算量是D_K ·D_K ·M ·D_F ·D_F.
这一部分的计算量是D_K ·D_K ·M ·D_F ·D_F.
pointwise convolution
使用1×1×N卷积生成最总需要的新feature map D_G × D_G × N.
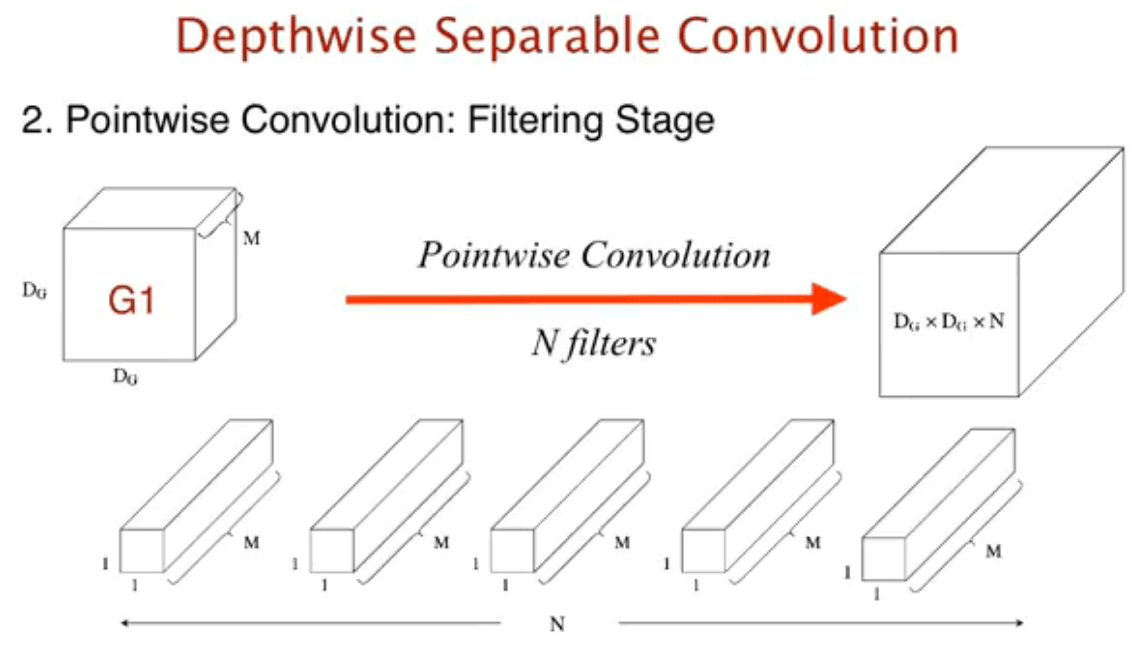 这一部分的计算量是N ·M ·D_F ·D_F
这一部分的计算量是N ·M ·D_F ·D_F
与标准卷积对比
所以总的计算量是: D_K ·D_K ·M ·D_F ·D_F +M ·N ·D_F ·D_F
 卷积参数对比
卷积参数对比
 可以看到, 在Depthwise Separable Convolution的计算量要比标准卷积要小很多. 具体的还需要看下面个个模型的应用.
可以看到, 在Depthwise Separable Convolution的计算量要比标准卷积要小很多. 具体的还需要看下面个个模型的应用.
MobileNet, v1
Architecture
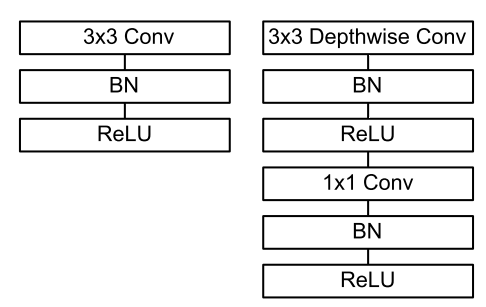
MobileNet将标准的卷积用Depthwise Separable Convolution替代, 每一个卷积后面都有Batchnorm和ReLU
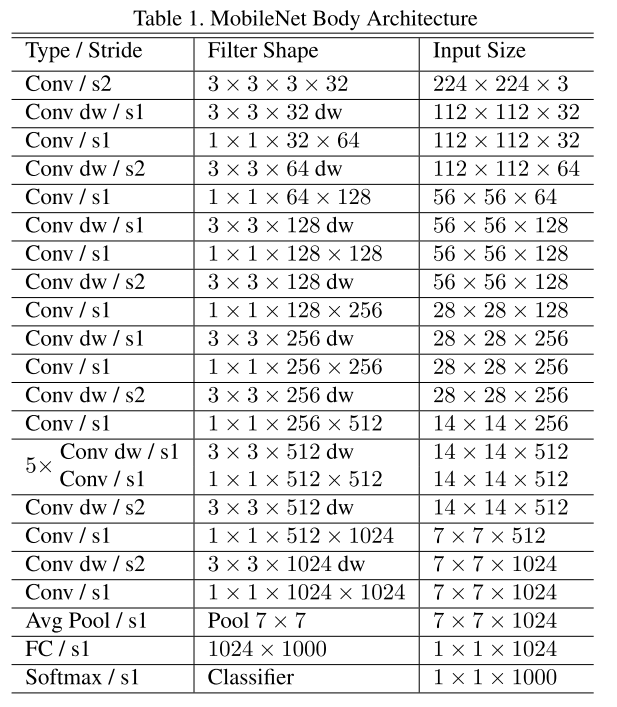
 下面是MobileNets完整结构, 把一个Depthwise Separable Convolution分成两层的话, 整个网络是28层.
下面是MobileNets完整结构, 把一个Depthwise Separable Convolution分成两层的话, 整个网络是28层.
training
相对其他大的模型, MobileNets模型结构小, 参数也少, 过拟合问题不大, 不需要太多的数据增强和正则.

optimization
MobileNet不仅结构上有了调整, 同时还引入了两个超参数, 让模型更小, 计算量更少.
Width Multiplier: Thinner Models
MobileNet 引入变量α, 任一层feature map 通道可以看成是αM, 输出通道为αN, α ∈ (0, 1] 可以选择 1, 0.75, 0.5 and 0.25. 这样的计算量为: D_K ·D_K · αM ·D_F ·D_F +αM · αN ·D_F ·D_F baseline MobileNet选择1, 如果需要更小的模型, 可以选择小一点的α, 可以根据需求作出调整
Resolution Multiplier: Reduced Representation
变量ρ的引入可以调整输入和输出的大小为ρD_F × ρD_F. 其中, ρ ∈ (0, 1] 1 为baseline, 图片大小为224, 通过调整ρ, 数据图片大小可以调整为224, 192, 160 或者 128. 引入ρ变量后的计算量为: D_K ·D_K ·αM·ρD_F ·ρD_F +αM·αN ·ρD_F ·ρD_F
Xception
Architecture
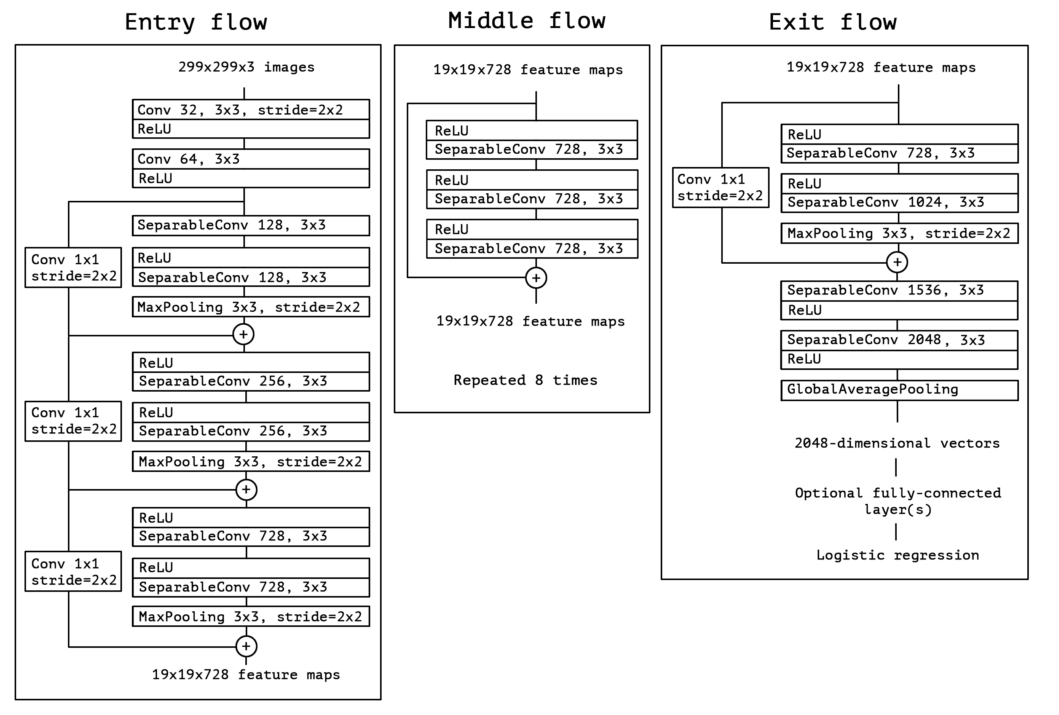
Xception是极端版本的inception, inception将卷积过程分解成跨通道和空间的相关关系(这个不是很看懂文章的意思), Xception的假设是, 这种跨通道和空间转换可以是完全分开的, 也就是Depthwise Separable Convolution.
inception 模块和Depthwise Separable Convolution有两个不同点. Depthwise Separable Convolution先做depthwise(空间上的)然后在1×1卷积, 而inception刚好相反, 其次, inception的每一个卷积后面都有激活函数, 而Depthwise Separable Convolution则没有.
所以最后的网络结构是36层网络结构, 可以看成是十几个Depthwise Separable Convolution的堆叠, 另外每个模块都添加了残差链接.
Reference
- https://www.youtube.com/watch?v=T7o3xvJLuHk
- MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
- Xception: Deep Learning with Depthwise Separable Convolutions